Sadržaj
Automated spear phishing using machine learning
Abstract
Phishing and spear phishing are one of the most effective ways to target an organization, because they target the weakest link of security - people. Bulk phishing is mostly automated where pre-made generic messages are being sent, achieving very low success rates ranging from 10% to 15%. On the other hand, spear phishing uses targeted messages which are handcrafted for the specific target and require studying the target and its interests, achieving better success rates compared to bulk phishing, reaching 45%.[3]
While machine learning in security has mostly been used in defensive manner with applications like malware and intrusion detection, it is necessary to also explore the use of machine learning for malicious attacks, since the technology (ML) is becoming widely publicly available and easy to use.
The purpose of this seminar is to show how machine learning can be used in an offensive manner to generate targeted malicious phishing messages, combining the benefits of bulk phishing (automated) and spear phishing (high success rate). This will be shown through the inspection of the tool SNAP_R [6], presented at DEF CON 2016.
Social media offers more benefits for this type of approach compared to email because of their strong incentive to disclose personal data, colloquial and short messages, bot-friendly API and the use of shortened URLs.
SNAP_R operates on twitter and uses the target's profile information, past timeline posts and the posts of users they retweet or follow to learn machine learning models (Markov model, LSTM) to generate personalized phishing messages with an embedded malicious link. It also identifies high value targets from a pool of targets based on their level of social engagement (number of followers, retweets, …) using specific rules or cluster-based algorithms.
A single running instance of the model outperformed a human in spear phishing over a 2-hour period, managing to get 275 victims out of 819 targeted to click the link (33.6% success), while the human managed to get 49 victims out of 129 targeted to click the link (38% success). The achieved results are comparable to large scale manual spear phishing campaigns, and the number of sent phishing tweets is arbitrarily scalable with the number of running instances of the tool, keeping in mind Twitter's rate limits.
The work is meant to foster greater awareness and understanding of spear phishing, specially on social media, and to raise awareness on the threats that machine learning tools can also be used in an offensive manner.
Introduction
Phishing is a social engineering technique that attempts to obtain sensitive information (such as passwords, credit card details, …) from the target, typically using email spoofing or instant messaging on social media. The target is typically redirected to a fake website which looks like the original website and requires input of sensitive information. Another possibility is malicious software installation (ransomware, keylogger, spyware, …) on the target's machine upon clicking on the malicious link.
Spear phishing is a targeted phishing attempt (directed at specific individuals or companies) which requires gathering data and profiling phishing targets. By gathering target's personal information and using it to gain the target's trust, it leads to an increased success rate compared to bulk phishing.
Spear phishing has grown to be the predominant vector used to compromise an organization [3].
Social media sites such as Facebook, Twitter, and LinkedIn, because of their strong incentive to disclose personal data, can provide an adversary with a wealth of information on the target’s work interests and expertise. Compared to email, it can be argued that social media's culture makes phishing easier since getting tweets from strangers is more common than getting an unexpected email, and shortened links are more commonly used.
These natural weaknesses at scale are just waiting to be exploited. How? Well that's when machine learning can come into play.
Machine Learning (ML) and Artificial Intelligence (AI) have become essential to many effective cybersecurity and defense strategies including malware detection, intrusion detection and phishing detection [5] .
While machine learning has mostly been used in a defensive manner in the security community, machine learning can also be utilized as a weapon to perform malicious attacks. In this case it's done by weaponizing social media.
Since inspecting and profiling targets is a critical and very time consuming measure which has to be taken in order to create a believable phishing message, automating this process could lead to more efficient spear phishing operating at a much larger scale with higher success rates.
Natural language processing is a subfield of AI that deals with raw unstructured text as a data source. It is particularly suitable for phishing because existing textual data can be used to identify the topics that the target is interested in and generate sentences which might be interesting to the target, and to which the target might respond.
In this seminar it will be discussed how threat actors can enhance the effectiveness of phishing attacks by using ML as a malicious tool for profiling the targets and generating phishing messages, describing the SNAP_R tool as an example.
SNAP_R tool overview
The work and tool SNAP_R (Social network automated phishing with reconnaissance, or snapper)[7] presented at DEF CON and BlackHat, 2016 [6] uses Twitter for automated spear phishing. Twitter has a lot of benefits which make it a suitable platform for automated spear phishing:
- access to extensive personal data
- bot-friendly API
- colloquial syntax
- use of shortened URL (can be used to obfuscate a phishing domain)
An example of a Twitter post :

Twitter profile example (taken from [6]):
Twitter posts are limited to 140 characters which reduces the probability of grammatical error compared to longer messages. All these points make it easier to generate more human-like messages and avoid suspicion.
The workflow of the tool [6]:
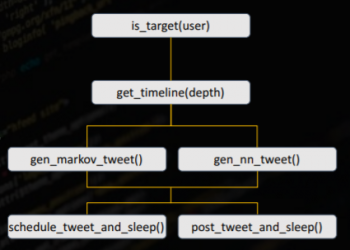
The first step is determining whether a user is a valid target. High value targets are identified based on their level of social engagement (number of followers, retweets, …), posted personal information (job, popularity, …), account details and click-rates of IP-tracked links.
The second step is timeline scraping of the target to a specified depth, obtaining information which will be used to generate a phishing post. (gen_markov_tweet(), gen_nn_tweet()).
SNAP_R uses a recurrent neural network or a Markov model trained on spear phishing pen-testing data and tweets, which will be described in more detail in the model training section.
The profiling of the users is done by extracting topics from the target's timeline posts and the users they retweet or follow. The ML model is used to generate fishing posts which contain an embedded shortened phishing link and an @mention, targeting specific users. One ot the topics of the target's tweets and replies is used to seed the RNN (recurrent neural network) or the Markov model for the phishing tweet generation.
The most frequent words (excluding the stopwords - words like the, in, at, that, which, …) were the most effective way for seeding [6]. The phishing tweet is sent within the hour that the target is most active (schedule_tweet_and_sleep()) or immediately (post_tweet_and_sleep()). The hour that the target is the most active at is determined by simply counting the total number of tweets in each hour.
The posted tweet is seen only by the people who follow both the target and the bot generating the message. That means that if the bot doesn't have any followers, the only one who can see the message is the target, which is desireable.
An example of a machine generated tweet :

Additional things that should be kept in mind are obeying the rate limit of Tweeter and posting non-phishing posts in order to build a believable profile and avoid detection. The authors also experimented with additional features such as the sentiment of the target's topics.
The tool and the techniques used to create it will be described in more detail in the following sections.
Automated target discovery
As mentioned, high value targets are selected based on their number of followers, tweets, retweets, posted personal information, …
From a large number of users high value targets can be selected using rule based methods and thresholds. For example valueing each feature (number of followers, how long the account exist, number of tweets, …) with a certain weight, and then multiplying each feature with the corresponding weight and summing up all those values. The higher the value, the higher the value of the target.
Another approach, that the authors explored [6] is using k-means++ [17] for clustering to cluster similar targets together. The number of clusters used in the algorithm is selected with grid search using the silhouette score [18] as the measure. The cluster containing high value targets can then mostly manually selected, or combined with previously mentioned rule based methods.
URL shortening
Other than keeping tweeter posts short, shortening the link also obfuscates the malicious link which the target might recognize, since there is a blacklist of known malicious links.
Not all shorteners allow shortening of malicious links, so [6] had to try out a number of them to find the one that is suitable. There are multiple options suitable, but goo.gl is used to shorten the malicious link since it provides additional features.
Some of the extra features are the target's browser, target's operating system, generating multiple unique shortened links for the same URL, …
No real malicious links were used during testing, the authors just measured the click-through rate.
Model training
Markov model
Markov model is a stochastic model used to model randomly changing systems, where future state depends only on the current state. The process is simple - transition probabilities (which are the probabilities of a word following the current word) are learned from the training set. The training set contained all of target's posts, and the probabilities were calculated by simply counting how many times the two words appear one after another and then normalizing by dividing with the total count for the given word to get probabilities.
For example if the training data has many instances of the phrase 'the cat in the hat' then if the model generates the word 'the' it will most likely generate 'cat' or 'hat' as the next word.
Example structure of a Markov model:
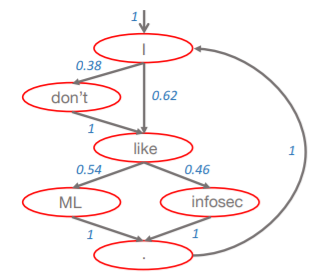
The next word is selecting using a 'fortune wheel selection', which means picking the next word with the corresponding probability. (For example in the picture, a random number from 0-1 is generated, if it's <0.38 'don't' is selected as the next word, otherwise 'like' is selected as the next word). This is done in such a manner to avoid always generating the most probable text sequence. It's smart to use words that started the sentence as the 'seed' (to start generating text) to avoid generating sentences like 'ate the cat' and similar.
Markov models are also agnostic to language, since they only use content on the target's timeline for training.
It's also possible to use a Markov chain of a higher order, where the future state doesn't depend only on the current state, but also on previous states. This means that a 2nd order Markov model would look at the previous 2 words to predict the next word.
Markov model of 2nd order was used here, and was implemented using python's markovify library.
LSTM
LSTM (Long-short term memory) is a type of a recurrent neural network (RNN) which has feedback connections between units and is suitable for sequential data (like text sentences) and capable of learning long-term dependencies. This model has been very successfully applied to a variety of problems ranging from speech recognition and language modeling to machine translation, because language is naturally sequential and words that are far apart may still be related to one another.
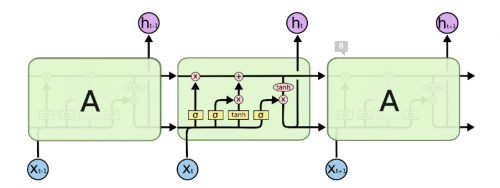
LSTM is a repeating chain-like structure composed of LSTM units. An LSTM unit is composed of a cell and 3 gates - input, output and the forget gate. The cell is used to remember values over time and the gates are used to control the information flow into and out of the cell.
The forget gate (lower left in the picture) is used to remove information from the cell state (top horizontal line). The input gate (middle 2) is used to update the cell state. The output gate (right) is used to filter the cell state and produce an output. Each of these gates has a matrix of weights (2 for input gate) which are learned using backpropagation since all functions used are differentiable. More details about how an LSTM works can be found in [12].
LSTM structure :
So how is an LSTM trained to generate words? First, it is necessary to somehow represent the words to the LSTM.
An LSTM for text generation can operate on character level, n-gram level and on word level. In the case of character level mode, characters are represented using one hot encoding, and the correct output of the LSTM should be next character in the sequence. This approach could be generalized to using n-grams (n-character parts of the word) [14]. In the case of word level mode, words are also represented using one-hot encoding or word embeddings [13], while the correct output of the LSTM should be the next word in the sequence. The loss used in optimization is (categorical) cross entropy loss.
The text is generated by seeding the LSTM with a starting word or a starting sequence of characters, and the output is comprised of ht's which are provided as input to the next cell of the LSTM chain. It is possible to stack multiple layers where ht's are inputs (xt's) to the next layer.
The authors train a word level LSTM comprised of 3 layers of about 500 units per layer (equal to the size of the hidden state ht) on Amazon EC2, using a dataset of 2M tweets (from @verified account comprised of tweets from verified users), which took about 5 days to train.
Comparison
The comparison showing the benefits and caveats of each model is shown in the next illustration taken from [6] :
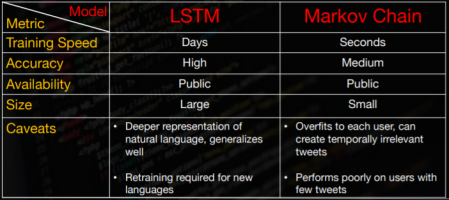
Results
An example of a generated message that has been successful in phishing :
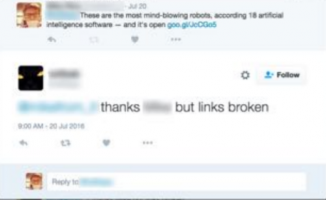
The success is measured by clickthrough rates on the shortened links in generated phishing messages.
The authors [6] reported that they achieved 17% clickthrough rates after 2 hours after posting 90 phishing posts (using #cat) and 30% clickthrough rate after 2 days. These results are significantly better than 5-14% reported in large-scale phishing campaigns [15] and comparable to reported 45% for large scale manual spear phishing [16]. The results are a consequence of social media risks and leveraging machine learning to target vulnerable users with a highly personalized message.
Comparison to a human
The authors [6] organized a competition between a human and SNAP_R tool. Over a two hour period they would target people with phishing posts, and whoever had the most clicks won.
The human was permitted to create as many Twitter characters as he/she wanted prior to the competition, and crafted pre-made tweets during the competition which he/she would copy and paste, tweak a bit and send to those posting the respective hashtags (#PokemonGo, #InfoSec, #GOPconvention).
Copying and pasting turned out to be a problem, as Twitter stops users from posting the same message too frequently.
A single instance of SNAP_R tool was run during 2 hours. SNAP_R sent phishing tweets to 819 users at 6.85 tweets/minute, which resulted in 275 victims, a 33.6% sucess rate. The number of sent phishing tweets is arbitrarily scalable with the number of running instances.
The human managed to send 129 phishing tweets (with copying and pasting pre-made tweets) at 1.075 tweets/minute with total 49 clickthroughs, a 38% success rate.
Conclusion
This type of work marks an advance in offensive capabilities by combining the advantages of bulk phishing (mostly automated, but low accuracy) and spear phishing (high accuracy, but mostly manual) through machine learning, and also as a way to show that machine learning can also be used as a weapon, other than using it for defense in security.
The approach lies on the fact that social media is emerging as an easy target for social engineering and phishing attacks. Twitter is used as a platform of interest because of its culture of exposing personal information, effective API (which allows crawling user's timelines and using bots), colloquial syntax, low bar for admissible messages and the use of shortened links. The approach could easily be tuned and applied to any similar social media platform.
The complete SNAP_R tool is fully data-driven : the models learn relevant textual characteristics of successful spear phishing on social media using target's data, and are used to generate tailored phishing messages for the targets. The results achieved (30-35%) are comparable to large scale manual spear phishing campaigns.
As spear phishing spam bots improve, the question is can Twitter (social networks) prevent them from taking over, and will people be able to distinguish real people from bots. These phishing vulnerabilities can be mitigated by using protected accounts which are immune to timeline scraping (on Twitter), detecting and limiting the use of bots, limiting publicly available personal data, and thinking twice about clicking on links.
The tool also serves as a way of fostering greater awareness and understanding of spear phishing and social engineering attacks, specially on social media, and aims to raise social media security awareness and education. It can also be used as an internal pen testing tool as a way to improve employee awareness and lead to better security education. Other use cases include staff recruiting and advertising.
Another main focus is raising awareness on the threats that machine learning tools can also be used in an offensive manner, since machine learning is rapidly becoming more and more automated. So it's necessary to be aware that 'black hats' will have more and more capabilities pretty soon.
Sources
[1] https://en.wikipedia.org/wiki/Phishing
[2]M. C. Kotson and A. Schulz. Characterizing phishing threats with natural language processing
[3]B. Grow and M. Hosenball, “Special report: In cyberspy vs. cyberspy, china has the edge,” 2011
[4] Bahnsen, A.C.; Torroledo, I.; Camacho, L.D.; Villegas, S. DeepPhish: Simulating Malicious AI.
[7] SNAP_R
[8] Would you fall for this Twitter phishing attack?
[9] goo.gl
[10] Markov model
[12]LSTM
[13] word embeddings
[14] n-grams
[16] Bursztein, Elie, et al. "Handcrafted fraud and extortion: Manual account hijacking in the wild."
[17] k-means ++
[18] silhouette score
