Sadržaj
Detekcija zlonamjernih URL-ova korištenjem tehnika strojnog učenja
Sažetak
Zastarjeli načini detekcije zlonamjernih URL-ova zahtijevaju velike baze podataka koje mogu detektirati samo URL-ove koji već postoje u bazi (blacklisted) ili koriste ekspertno kreirane značajke čija izrada iziskuje ogromnu količinu vremena i novčanih resursa. U ovom seminaru predstavlja se novi model dubokog učenja, grane strojnog učenja, koji automatski ekstrahira informativne značajke iz sirovog URL-a koristeći embeddinge na razini znakova, slojeve bi-LSTM-a kako bi kontekstualizirao vektorske reprezentacije svakog znaka te na poslijetku potpuno povezane slojeve koji vrše krajnju klasifikaciju zlonamjernosti URL-a. Model na skupu od 420464 primjera uz 5-fold evaluaciju postiže prosječnu točnost od 98,4% te F1 mjeru od 97,2%. Kompletan kod dostupan je na github-u: https://github.com/davor10105/MaliciousURLDetection
Ključne riječi: zlonamjerni URL-ovi, detekcija, strojno učenje, duboko učenje, mrežna forenzika
Uvod
Uobičajeni pristup detekciji zlonamjernih URL-ova zahtijeva velike baze označenih podataka koje služe kao jednostavan lookup dictionary ili kao ulaz u hashing algoritam koji će dati konačnu odluku o zlonamjernosti danog URL-a. Noviji pristupi pokušavaju kombinirati ekstrakciju ekspertno odabranih značajki s plitkim modelima poput SVM-a kako bi klasificirali URL. I jedan i drugi pristup imaju svoje mane, prvi pristup kao problem ima nemogućnost detekcije novih oblika URL-ova sve dok se takav primjer ne nađe u samoj bazi. Drugi pristup za manu ima ogromnu količinu vremena i resursa koje eksperti moraju utrošiti za kreiranje, a s time i održavanjem dovoljno informativnih značajki za točnu klasifikaciju. Primjerice, različite značajke bi se mogle kreirati i za različite tipove zlonamjernih URL-ova - spam, phishing ili malware URL-ove.
Kako cyber-napadi napreduju iznimno brzo, tako i modeli za detekciju moraju biti dinamični i u mogućnosti brzo se prilagoditi novim načinima napada, što čini ručnu konstrukciju korisnih značajki presporom. Kao rješenje ovog problema dolazi duboko učenje i model predstavljen u ovom seminaru koji uz dani sirovi ulaz znakova URL-a automatski kreira informativne značajke i uspješno klasificira njihovu zlonamjernost. Niže su prikazani primjeri benignih i zlonamjernih URL-ova koji se mogu naći u skupu za učenje.
| URL | zlonamjeran? |
|---|---|
| crackspider.us/toolbar/install.php?pack=exe | da |
| brr.com.au/event/82765/grant-anderson-partner | ne |
Primjer zlonamjernog i benignog ulaznog primjera u model.
Strojno učenje
Embeddings
Kako bi se pojedini URL mogao koristiti kao ulaz u neuronsku mrežu, potreban je način predočavanja samog niza znakova u niz korisnih značajki koje bi model tijekom treninga mogao učiti. U tu svrhu, u ovom seminaru se koriste embeddingsi na razini znakova. Embeddingsi su preslikavanje iz diskretne varijable (u ovom slučaju jednoga znaka) u vektor kontinuiranih vrijednosti koje nose više informacija od same činjenice o kojemu se znaku radi - primjerice u kojem se kontekstu taj znak najčešće pojavljuje, odnosno koji znakovi ga najčešće okružuju, što indirektno modelu pruža informaciju o sintaksi ulaznog jezika.
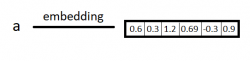
Preslikavanje znaka 'a' u embedding vektor.
Povratne neuronske mreže
Povratne neuronske mreže se koriste za procesiranje sekvencijalnih podataka, najčešće teksta. Ovdje je korištena arhitektura LSTM (Long Short-Term Memory ćelija) koja omogućuje prijenos informacija čak i kroz dulje sekvence te djelomično rješava problem nestajućeg/eksplodirajućeg gradijenta, što je veliki problem prilikom treniranja standardne RNN arhitekture. LSTM ćelija se sastoji od cell-a, input gate-a, output gate-a i forget gate-a. Cell pamti informacije tijekom cijele sekvence, dok gate-ovi reguliraju protok informacija izvan i unutar samog cell-a.
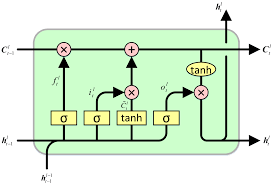
Unutarnja arhitektura LSTM ćelije, preuzeto s [4]
Jednodimenzionalni sloj sažimanja
Sloj sažimanja je oblik nelinearnog down-sampling-a ulaza. Najčešće korišteni oblik je maksimum sažimanje, koje dijeli ulazni niz na sekcije te vraća maksimalnu vrijednost svake. Intuitivno, točna lokacija značajke unutar vektora je manje bitna od činjenice da je ona iznimno aktivna u odnosu na njezino neposredno susjedstvo, što je upravo i motivacija za korištenje ovog sloja - izbacuje “nebitne”, slabo aktivne značajke i dalje prosljeđuje samo značajke koje će biti korisne nižim slojevima što na kraju smanjuje i broj potrebnih parametara, količinu memorije i vrijeme izračuna te pomaže kod problema prenaučenosti na podacima učenja.
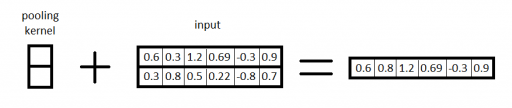
Primjer izlaza jednodimenzionalnog sloja sažimanja.
Potpuno povezani sloj
Potpuno povezani sloj je najjednostavniji i najčešće korišteni sloj unutar modela koji koriste neuronske mreže. Svaki neuron jednog sloja je povezan s neuronom drugog sloja što omogućuje modelu da konstruira čitav niz novih značajki od kojih će svaka imati informaciju te biti ovisna o svim značajkama prethodnog sloja. No, takva informiranost svakog neurona dovodi do velikog broja potrebnih parametara i potrebne memorije te čestog problema prenaučenosti, zbog čega se obično između slojeva koriste razne tehnike regularizacije te se sami slojevi koriste tek u zadnjim slojevima mreže, gdje je količina značajki mala, a gustoća korisnih informacija velika.
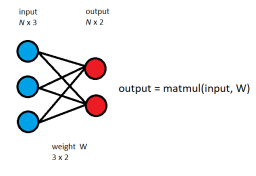
Definicija potpuno povezanog sloja.
Metoda
Model koji je korišten u ovom seminaru temelji se na pretpostavci da sami nizovi znakova unutar URL-a pružaju bolju informaciju od ručno dizajniranih značajki koje su se koristile u ranijim pristupima ovom problemu. U ovoj sekciji je opisana potpuna arhitektura modela korištenog za klasifikaciju danih URL-ova kao zlonamjerne ili benigne. Model je implementiran u Python-u 3.7 unutar Pytorch biblioteke.
Arhitektura
Sam model se može podijeliti u tri razine: embedding znakova, slojevi bi-LSTM-a koji embedding-e znakova pretvaraju u kontekstno ovisne reprezentacije te potpuno povezani sloj koji koristi prethodno ekstrahirane značajke kako obavio krajnju klasifikaciju. Znakovi koji se prevode u vektorsku reprezentaciju su 85 znakova koji su dopušteni unutar URL-ova, dok se svi ostali označavaju labelom [UNK] te se i njihova vektorska reprezentacija može učiti tijekom faze učenja. Također, uvedena je i labela [PAD] koja služi za padding samih URL-ova kako bi se duljina svakog dovela na fiksnu duljinu i omogućila korištenje batch-eva tijekom učenja. Fiksna duljina URL-a je postavljena na s = 128, dok je veličina batch-a postavljena na N = 128.
Model kao ulaz dobiva batch nizova znakova duljine s te ih pretvara u njihovu vektorsku reprezentaciju (embedding) pomoću jednostavnog lookup dictionary-a, gdje je svakom znaku, neovisno o znakovima prije ili poslije njega, dodijeljen vektor floating point brojeva duljine d, tvoreći tenzor veličine N × s × d za svaki ulazni URL. Ova embedding razina modela se kao i ostale, optimizira tijekom učenja pomoću backpropagation-a, čineći vektorske reprezentacije znakova informativnijima o njihovoj funkciji unutar URL-a. Veličina embeddinga postavljena je na d = 32 te su reprezentacije nakon smanjenja dimenzionalnosti pomoću algoritma T-SNE prikazane na sljedećoj slici.

Prikaz embeddinga korištenih znakova u dvodimenzionalnom prostoru nakon smanjenja dimenzionalnosti T-SNE algoritmom.
Ovdje se jasno vidi kako slične reprezentacije imaju semantički slični znakovi, primjerice velika i mala slova su zasebno grupirana te se uočava i grupa kontrolnih znakova unutar URL-ova.
Sljedeća razina modela je konstruirana od dva sloja bi-LSTM ćelija koje ulazne vektorske reprezentacije neovisne o kontekstu, odnosno ostalim znakovima URL-a preslikava u kontekstno ovisne reprezentacije. Na taj način, čak i isti znakovi mogu imati potpuno različite vektorske reprezentacije te je motivacija ove razine modela da pomoću tih novih reprezentacije uspije ekstrahirati korisne informacije o danom nizu znakova koje će se koristiti kao značajke potrebne za konačnu klasifikaciju u zadnjoj razini. Razina kao ulaz dobiva izlaz prethodne - embedding razine, tenzor dimenzija N × s × d kojem se transponiraju dimenzije 0 i 1 prije ulaska u bi-LSTM tako da se dobije tenzor s × N × d. Pošto za svaki znak ulaznog niza bi-LSTM, za razliku od običnog LSTM-a, računa skriveno stanje gledajući niz unaprijed i unatrag, te dvije skrivene reprezentacije se na izlazu konkateniraju. Veličina skrivenog stanja bi-LSTM-a je postavljena na h = 128, tako da će izlaz ove razine biti s × N × (2 · h).
Zadnja razina modela je razina klasifikacije. Prvo se izlaz prethodne razina provlači kroz sloj jednodimenzionalnog sažimanja kernel-a veličine s. maksimum sažimanje za zadaću ima iz cijele sekvence izvući samo značajke koje imaju najveću aktivaciju unutar sekvence kako bi se za svaku dobio jedinstveni vektor. Ovaj sloj ulazni tenzor (dimenzija N × (2 · h) × s nakon transpozicije) preslikava u matricu dimenzija N × (2 · h). Nakon toga se koriste dva standardna potpuno povezana sloja, veličina d1 = 128 i d2 = 2 (binarna klasifikacija) koja ekstrahirane značajke prethodnog sloja prevode u krajnju odluku o zlonamjernosti URL-a.
Kako bi se spriječila prenaučenost modela na danim podacima, koriste se dvije tehnike regularizacije: batch normalizacija i dropout. Batch normalizacija se koristi iza slojeva bi-LSTM ćelija te između potpuno povezanih slojeva, dok se dropout s parametrom p postavljenim na 0.2 koristi između slojeva bi-LSTM-a.
Rezultati
Model je učen na skupu od 420464 URL-ova od kojih je 344821 (78%) benigno, a 75643 (22%) zlonamjerno. Zlonamjerni URL-ovi su kombinacija phishing, spam i malware URL-ova. Evaluacija modela je provedena pomoću 5-fold tehnike, a na svakom foldu model je učio kroz 10 epoha na podacima podijeljenim u batch-eve veličine 128. Kao funkcija gubitka korištena je funkcija unakrsne entropije, a nju se optimiziralo pomoću optimizatora Adam s faktorom učenja postavljenim na 5 · 10-5 , i parametrima skaliranja gradijenta i kvadrata gradijenta 0.8 i 0.999.
U nastavku su prikazane srednje vrijednosti točnosti, preciznosti, recall-a i F1 mjere na 5 foldova te ROC krivulja na foldu s najvećom točnosti. Na njoj se također vidi da je trenutno najveća greška modela nemogućnost detekcije svih malicionih URL-ova unutar testnog skupa, odnosno manji recall.
| Točnost | Preciznost | Recall | F1 |
|---|---|---|---|
| 98,4% | 97,7% | 96,7% | 97,2% |
Prosječni rezultati evaluacije na 5 foldova.
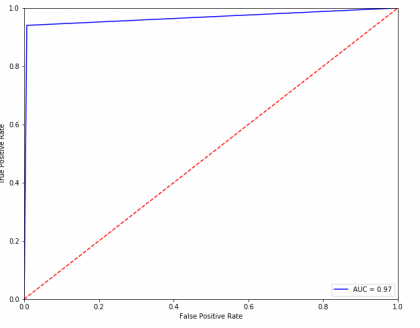 ROC krivulja modela na foldu na kojemu su postignuti najbolji rezultati.
ROC krivulja modela na foldu na kojemu su postignuti najbolji rezultati.
Zaključak
U sklopu seminara implementiran je potpuno novi model za detekciju zlonamjernih URL-ova temeljen na tehnikama strojnog učenja. Korištenjem embeddinga i bi-LSTM ćelija kako bi se dobila kontekstno ovisna vektorska reprezentacija svakog niza, model ekstrahira bitne značajke koje su učene direktno iz velikog skupa podataka i koristi ih kako bi s velikom točnošću odredio krajnju klasifikaciju. Model pokazuje kako je ovakve rezultate moguće dobiti iz jednostavnog niza ulaznih znakova, bez potrebe za ručno izrađenim značajkama ljudskih eksperata. Rezultati bi se naravno, mogli i poboljšati korištenjem drugih informacija uz sam URL, na primjer informacijama dobivenim korištenjem whois servisa poput lokacije IP adrese. Također, korišteni skup podataka je relativno malen te bi se proširenjem unaprijedile i performanse modela.
Sources
[1] Malicious and non-malicious URL dataset, Kaggle https://www.kaggle.com/antonyj453/urldataset
[2] Beyond the Blacklists: Detecting Malicious URL Through Machine Learning, Youtube https://www.youtube.com/watch?v=Kd3svc9HZ0Y
[3] eXpose: A Character-Level Convolutional Neural Network with Embeddings For Detecting Malicious URLs, File Paths and Registry Keys, arXiv https://arxiv.org/pdf/1702.08568.pdf
[4] Long short-term memory, Wikipedia https://en.wikipedia.org/wiki/Long_short-term_memory
[5] Pytorch documentation, Pytorch https://pytorch.org/docs/stable/index.html
[6] Sklearn documentation, scikit-learn https://scikit-learn.org/stable/
