Sadržaj
Klasifikacija datotečnih fragmenata
Sažetak
U ovom seminarskom radu kratko ću objasniti neke značajke datoteka, što je to datotečna fragmentacija, te zašto do nje dolazi. Također ću opisati nekoliko algoritama koji se koriste za klasifikaciju datotečnih fragmenata. To su algoritmi strojnog učenja: kNN, konvolucijske i neuronske mreže.
Uvod
Klasifikacija datotetčnih fragmenata igra važnu ulogu u digitalnoj forenzici. Dokazi se mogu naći u izbrisanim/skrivenim fragmentima. Tehnologije rezbarenja datoteka obično se primjenjuju za rekonstrukciju datoteka iz tih fragmenata za daljnje forenzičko istraživanje. Ispravno klasificiranje ovih fragmenata nužan je korak za učinkovito rezbarenje datoteka. Inače, rezbarenjem datoteka bi morali isprobati sve kombinacije ogromnog broja datotečnih fragmenata i to bi rezultiralo ogromnim računskim troškom. Osim toga, točnost klasifikacije datotečnih fragmenta značajno utječe i na točnost rezbarenja datoteke budući da pogrešno klasificirani fragmenti predstavljaju šum na ulazu.
Rana istraživanja o klasifikaciji datotečnih fragmenata koriste punu ekstenziju datoteke, čarobni broj ili metapodatke datoteka. Ove metode imaju visoku točnost klasifikacije samo kada se metapodaci mogu pronaći i izdvojiti iz medija za pohranu s fragmentima. Stoga imaju manje praktične primjene u digitalnoj forenzici jer metapodaci datotečnih fragmenata obično u stvarnim slučajevima nedostaju.
Posljednjih godina predloženi su algoritmi za klasifikaciju datotečnih fragmenata temeljeni na sadržaju koji izdvajaju N-gram, Shannonovu entropiju, Hammingovu težinu i statističke pravilnosti bajtova. U nekim shemama koriste se tradicionalne tehnike strojnog učenja kako bi se poboljšala izvedba ovih algoritama klasifikacije. Međutim, za datoteke visoke entropije kao što su komprimirane datoteke (npr. zip datoteka ili .jpg datoteka) i šifrirane datoteke, točnost nije toliko visoka koliko se očekivalo.
Ali, da krenemo od početka, pogledajmo prvo kako funkcioniraju datoteke.
Datoteke općenito
U operacijskom sustavu datoteka je osnovna jedinica za pohranu koja se koristi za čuvanje podataka i informacija. Na niskoj razini, datoteka je predstavljena nizom binarnih znamenki (1 i 0) koje su pohranjene na fizičkom uređaju za pohranu kao što je tvrdi disk ili SSD disk.
Kada se proizvoljna datoteka spremi na disk, operacijski sustav poduzima nekoliko koraka za pohranu podataka na fizički uređaj za pohranu. Evo općeg pregleda procesa:
1. Korisnik ili program pokreće operaciju spremanja datoteke, navodeći naziv datoteke i mjesto na koje će se datoteka spremiti.
2. Operativni sustav provjerava datotečni sustav kako bi utvrdio ima li dovoljno prostora na disku za spremanje datoteke. Ako nema dovoljno dostupnog prostora, operativni sustav može zatražiti od korisnika da oslobodi prostor brisanjem drugih datoteka ili dodijeli dodatni prostor na disku ako je moguće.
3. Operativni sustav dodjeljuje niz susjednih klastera na disku za držanje datoteke. Veličina svakog klastera može varirati ovisno o datotečnom sustavu koji se koristi i veličini datoteke.
4. Operativni sustav zapisuje sadržaj datoteke u dodijeljene klastere na disku, koristeći upravljački program datotečnog sustava za upravljanje detaljima niske razine čitanja i pisanja podataka na disk.
5. Operativni sustav ažurira metapodatke datotečnog sustava kako bi zabilježio lokaciju datoteke na disku i druge detalje kao što su veličina datoteke, datum stvaranja i dopuštenja.
6. Datoteka je sada spremljena na disk, a korisnik ili program joj mogu pristupiti po potrebi u budućnosti.
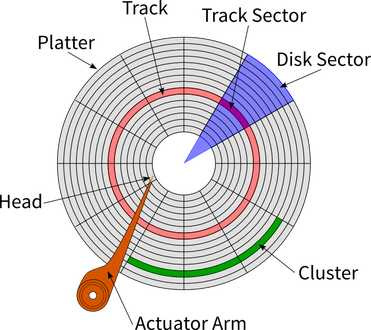
Na slici 1. prikazani su pojedini logički dijelovi diska:
Datotečna fragmentacija
Slika 2. prikazuje datotečnu fragmentaciju na disku:

Korištenjem računala mi spremamo i brišemo razne datoteke, nakon nekog vremena stvaraju se mali fragmenti na disku u koju se ne može spremiti cijela datoteka, ali može dio. Jedna datoteka spremi se u nekoliko malih dijelova koji se zovu datatotečni fragmenti.
Ovo ponašanje uglavnom nije problem u praksi, jedino u sustavima visokih performansi gdje je brzina čitanja s diska vrlo bitna. Problem nam stvaraju moguće greške ili oštećenja diska kod kojih dolazi do gubitka opisnika datoteka. Bez opisnika datoteke mi više ne znamo što je njen sadržaj, koja je njena ekstenzija niti kolike je veličine. Ovaj problem se u praksi rješava klasifikacijom datotečnih fragmenata. Postoje tri različita pristupa:
1. Čarobni bajtovi
Čarobni bajt nije ništa drugo nego prvih nekoliko bajtova datoteke koji se koriste za prepoznavanje datoteke. Ne vidi se ako otvorite datoteku. Ali može se vidjeti pomoću nekih posebnih alata. Sve varijante Linuxa imaju alat koji se zove “file” koji vam govori o kakvoj se datoteci radi. Ova metoda je jako spora jer zahtijeva prepoznavanje čarobnih bajtova i njihovo uspoređivanje s bazom unaprijed definiranih čarobnih bajtova kako bi se otkrio tip datoteke.
2. Esktenzija
Ovo je najjednostavniji način određivanja tipa datoteke.
3. Provjera sadržaja datoteke
U ovom području prelazimo na algoritme strojnog učenja.
Algoritmi
kNN
K-najbližh susjeda (kNN) vrsta je nadziranog algoritma učenja koji se koristi i za regresiju i za klasifikaciju. KNN pokušava predvidjeti točnu klasu za testne podatke izračunavanjem udaljenosti između testnih podataka i svih točaka treninga. Zatim odabere k broj točaka koje su najbliže podacima testa.
kNN algoritam izračunava vjerojatnost da testni podaci pripadaju klasama podataka o obuci 'K' i bit će odabrana klasa koja ima najveću vjerojatnost. U slučaju regresije, vrijednost je srednja vrijednost 'K' odabranih točaka treninga.
Kostur algoritma:
1. Izabere se k > 0 i uzorak
2. Izabere se k ulaza najbližih uzorku
3. Izračunamo klasifikaciju ulaza pomoću Euklidske udaljenosti
4. Istu tu klasifikaciju odredimo za uzorak

Rad u kojem se koristi neuronska mreža za klasifikaciju datotečnih fragmenata: [5]
Neuronske mreže
Neuronska mreža vrsta je algoritma strojnog učenja koji je dizajniran za simulaciju ponašanja ljudskog mozga pri obradi i analizi informacija. Sastoji se od više međusobno povezanih slojeva umjetnih neurona koji zajedno rade na prepoznavanju uzoraka i predviđanju.
Navedeni umjetni neuroni zovu se perceptroni. Perceptron uzima jedan ili više binarnih ulaza i proizvodi jedan binarni izlaz. Djeluje množenjem svakog ulaza s težinom, zbrajanjem ponderiranih ulaza, a zatim primjenom funkcije praga na rezultat kako bi se dobio izlaz.
Funkcija praga obično je stepenasta funkcija koja daje 1 ako je ulaz iznad određenog praga, a 0 u suprotnom. Prag je također predstavljen kao težina, koja se množi s konstantnim ulazom od 1. Stoga se izlaz perceptrona izračunava na sljedeći način:
izlaz = prag (ponderirani_zbroj)
gdje je ponderirani zbroj, zbroj inputa pomnožen njihovim odgovarajućim ponderima:
ponderirani_zbroj = (ulaz1 * težina1) + (ulaz2 * težina2) + … + (ulazn * težinan)
Tijekom treninga, težine se prilagođavaju na temelju pogreške između predviđenog izlaza i stvarnog izlaza. Prilagodba se vrši pomoću pravila učenja kao što je delta pravilo ili pravilo učenja perceptrona, koja ažuriraju težine u smjeru koji smanjuje pogrešku.
Jedan perceptron može riješiti samo linearno odvojive probleme, gdje se podaci mogu razdvojiti ravnom linijom. Međutim, kombiniranjem višestrukih perceptrona moguće je stvoriti složenije arhitekture neuronskih mreža koje mogu riješiti nelinearne probleme. Slika 3. prikazuje perceptron:

Rad u kojem se koristi neuronska mreža za klasifikaciju datotečnih fragmenata: [1]
Konvolucijske mreže
Konvolucijske neuronske mreže (CNN) vrsta su umjetne neuronske mreže koja je posebno dizajnirana za obradu podataka koji imaju mrežnu strukturu, kao što su slike, video ili audio. Često se koriste za zadatke prepoznavanja slika i klasifikacije, kao i za druge primjene kao što je obrada prirodnog jezika i prepoznavanje govora.
Glavna razlika između CNN-a i običnih neuronskih mreža je u tome što su CNN-ovi dizajnirani za rad s podacima koji imaju strukturu sličnu mreži, dok su obične neuronske mreže prikladnije za rad s podacima koji imaju linearnu ili sekvencijalnu strukturu. U običnoj neuronskoj mreži svaki neuron u jednom sloju povezan je sa svakim neuronom u sljedećem sloju. To znači da mreža može naučiti prepoznavati obrasce u podacima koji nisu nužno prostorno povezani.
Nasuprot tome, u CNN-u, neuroni su organizirani u “slojeve” koji su posebno dizajnirani za obradu ulaznih podataka s prostornom strukturom. Slojevi u CNN-u obično uključuju konvolucijske slojeve, skupne slojeve i potpuno povezane slojeve. U konvolucijskom sloju, mreža primjenjuje skup filtera na ulazne podatke, pri čemu svaki filter uči prepoznati određeni uzorak u ulazu. Izlaz konvolucijskog sloja zatim prolazi kroz sloj za udruživanje, koji smanjuje prostorne dimenzije izlaza, dok zadržava najvažnije značajke. Na kraju, izlaz prolazi kroz potpuno povezani sloj, koji obavlja konačnu klasifikaciju ili zadatak regresije. Slika 4. prikazujejednu konvolucijsku neuronsku mrežu:

Rad u kojem se koristi konvolucijska neuronska mreža za klasifikaciju datotečnih fragmenata: [3]
Zaključak
U ovom seminarskom radu kratko su objašnjene neke značajke datoteka, što je to datotečna fragmentacija, te zašto do nje dolazi. Također je opisano nekoliko algoritama koji se koriste za klasifikaciju datotečnih fragmenata. Osim toga dani su primjeri znanstvenih radova u kojima se koriste navedeni algoritmi. Od svih algoritama izdvojio bih algoritam [1] kao najbrži i najpouzdaniji. Iz istih razloga baš je taj algoritam naveden u prikaznicama na predmetu, te se preporučuje da se upravo njega koristi za klasifikaciju datotečnih fragmenata u industriji.
